Le crawl budget est souvent le parent pauvre du SEO technique, jusqu'au jour où Google n'indexe plus vos nouveaux produits. Sur un catalogue de 50 000 SKUs, chaque requête Googlebot est précieuse. Voici comment diagnostiquer et optimiser concrètement le crawl budget de votre PrestaShop.
Qu'est-ce que le crawl budget et pourquoi c'est critique en e-commerce ?
Le crawl budget est le nombre de pages que Googlebot consent à crawler sur votre site dans un intervalle de temps donné. Il est déterminé par deux facteurs :
- Crawl rate limit : la vitesse à laquelle Googlebot peut crawler sans surcharger votre serveur (déterminé par le temps de réponse et les erreurs)
- Crawl demand : l'intérêt de Google pour vos URLs (popularité, fréquence de mise à jour)
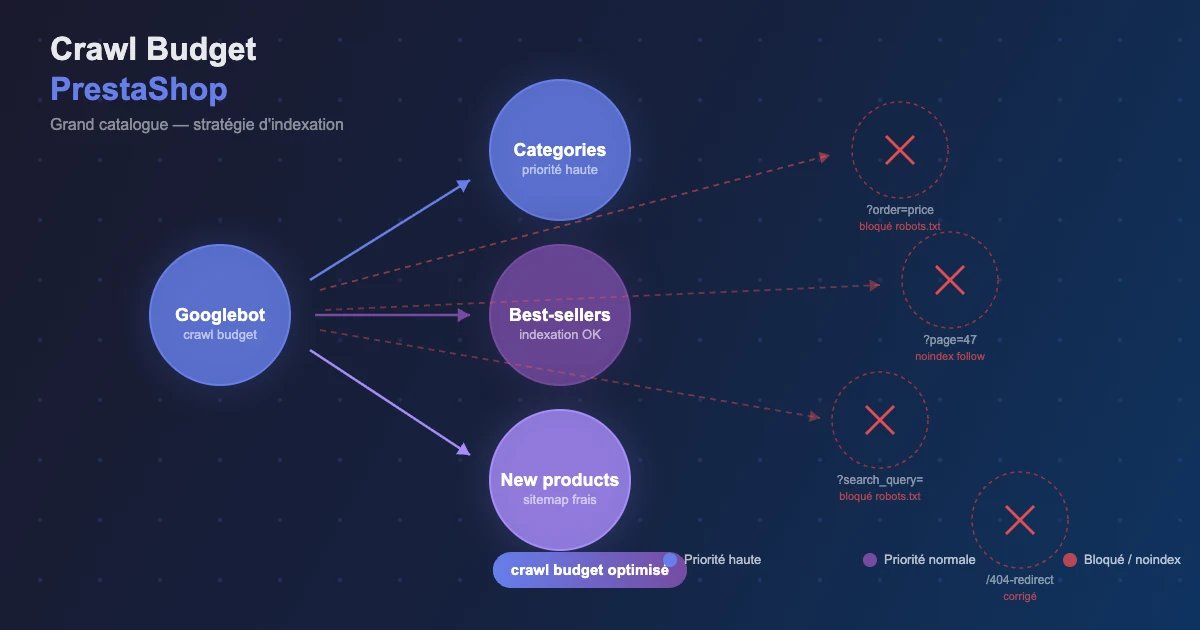
En e-commerce, le problème est structurel : un catalogue de 30 000 produits génère facilement 200 000+ URLs indexables si vous ne gérez pas les facettes, les tris, les paramètres de pagination. Google gaspille son crawl budget sur des URLs de faible valeur et ne crawle jamais vos nouvelles fiches produit.
Symptômes concrets : un produit lancé il y a 3 semaines n'apparaît pas dans les SERP, ou Google Search Console signale des URLs "Discovered – currently not indexed" qui s'accumulent.
Étape 1 : auditer le crawl actuel avec les logs serveur
Avant d'agir, mesurer. Les logs Apache/Nginx sont la source de vérité sur ce que Googlebot crawle réellement.
Extraire les requêtes Googlebot
# Nginx — extraire les accès Googlebot des 30 derniers jours
grep "Googlebot" /var/log/nginx/access.log | \
awk '{print $7}' | \
sort | uniq -c | sort -rn | head -100
Ce que vous cherchez :
- Quelle proportion du crawl va sur des URLs avec paramètres (
?order=price_asc,?page=5) ? - Googlebot passe-t-il du temps sur des URLs
noindexou des 404 ? - Quel est le temps de réponse moyen pour Googlebot ?
Identifier les URL "pièges à crawl"
# Compter les URLs avec paramètres de tri/filtre
grep "Googlebot" /var/log/nginx/access.log | \
grep -E "\?(order|id_|filter_|price|page)=" | \
wc -l
Si ce chiffre représente plus de 30% de votre crawl total, vous avez une fuite majeure de crawl budget.
Étape 2 : bloquer les URL sans valeur SEO
robots.txt : la première ligne de défense
Dans PrestaShop, le robots.txt est générable depuis le back-office (SEO & URLs), mais il est souvent insuffisant. Voici une base robuste :
User-agent: *
# Paramètres de tri et filtres sans valeur SEO
Disallow: /*?order=
Disallow: /*?id_currency=
Disallow: /*?isolang=
Disallow: /*?search_query=
Disallow: /*?controller=search
# Pagination profonde (après page 3)
# À ajuster selon votre pagination canonique
Disallow: /*?page=
# Pages d'administration et back-office
Disallow: /admin*/
Disallow: /modules/
# URLs de session (si non gérées côté serveur)
Disallow: /*?token=
Disallow: /*sid=
# Doublons techniques courants PrestaShop
Disallow: /index.php?
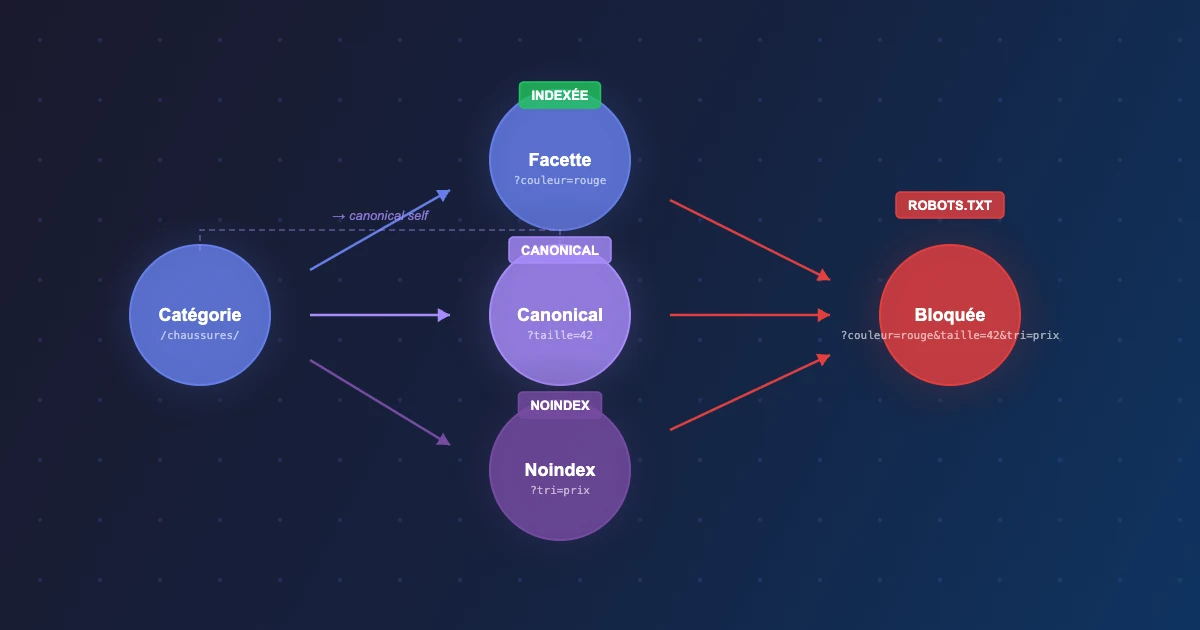
Attention : ne bloquez pas les URLs de facettes si elles ont des canonicals vers la catégorie parente. Blocage et noindex ne servent pas les mêmes objectifs.
Override du controller Robots dans PrestaShop
Pour une gestion programmatique, overridez le controller robots :
// override/controllers/front/RobotsController.php
class RobotsController extends RobotsControllerCore
{
public function initContent(): void
{
parent::initContent();
// Ajout dynamique des paramètres à bloquer
$this->addDisallowRules();
}
private function addDisallowRules(): void
{
$dynamicRules = [
'/*?order=',
'/*?search_query=',
'/*' . Configuration::get('PS_TOKEN_ENABLE') === '1' ? '?token=' : '',
];
foreach ($dynamicRules as $rule) {
if (!empty($rule)) {
$this->robots_txt .= 'Disallow: ' . $rule . PHP_EOL;
}
}
}
}
Étape 3 : gérer les pages de faible valeur avec noindex
Le robots.txt bloque le crawl mais ne consolide pas le PageRank. Pour les pages que vous voulez que Googlebot crawle (pour suivre les liens) mais pas indexer, utilisez noindex.
Cas d'usage typiques PrestaShop
- Pagination : page 2, 3, 4... sans canonical –
noindex, follow - Tris produits : même catégorie triée par prix –
noindex, follow - Produits hors stock depuis plus de 90 jours : selon votre stratégie
- Variantes isolées : si chaque combinaison a sa propre URL
Hook hookDisplayMetaTags pour le noindex dynamique
// Dans votre module ou override
public function hookDisplayMetaTags(array $params): string
{
$controller = $this->context->controller;
if ($this->shouldNoindex($controller)) {
return '';
}
return '';
}
private function shouldNoindex(FrontController $controller): bool
{
// Pagination > page 1
if ($controller instanceof CategoryControllerCore) {
$page = (int) Tools::getValue('page', 1);
if ($page > 1) {
return true;
}
}
// Paramètre de tri actif
if (Tools::getValue('order')) {
return true;
}
return false;
}
Étape 4 : optimiser la vitesse de crawl
Le crawl rate limit dépend directement de votre temps de réponse. Un serveur qui répond en 800 ms sera crawlé 3 à 5 fois moins vite qu'un serveur à 150 ms.
Cache serveur dédié au crawl Googlebot
Une technique efficace : servir directement du cache à Googlebot, sans PHP, pour maximiser la vitesse de crawl sans surcharger votre infrastructure :
## Nginx — cache prioritaire pour Googlebot
map $http_user_agent $is_bot {
default 0;
~*Googlebot 1;
~*bingbot 1;
}
server {
# ...
location / {
# Pour les bots, servir le cache en priorité
if ($is_bot) {
try_files $uri /cache/page/$uri/index.html @php;
}
try_files $uri @php;
}
location @php {
fastcgi_pass php-fpm;
# config FastCGI standard...
}
}
Vérifier les redirections en chaîne
Chaque redirect consomme du crawl budget. Un produit déplacé de catégorie peut générer une chaîne de 301 → 302 → 200. Auditez avec Screaming Frog ou via vos logs :
# Trouver les redirections que Googlebot suit
grep "Googlebot" /var/log/nginx/access.log | \
awk '$9 ~ /30[12]/ {print $7, $9}' | \
sort | uniq -c | sort -rn | head -50
Étape 5 : prioriser l'indexation des pages à haute valeur
Sitemap segmenté par priorité
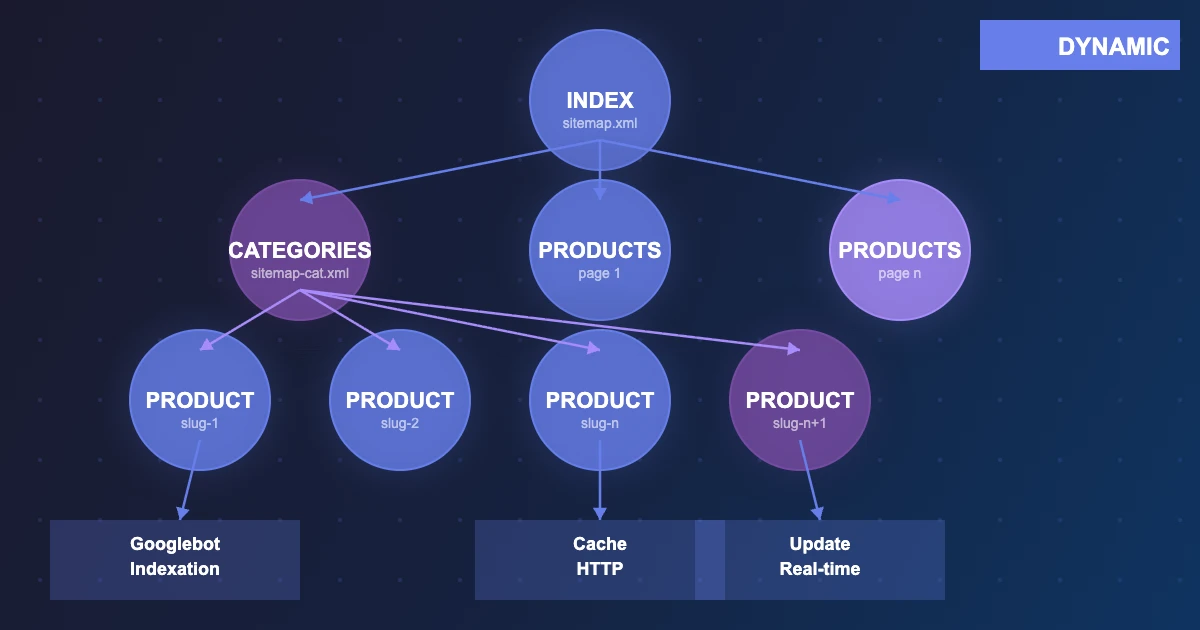
Ne mettez pas 50 000 URLs dans un seul sitemap avec la même priorité. Segmentez pour guider Googlebot :
<!-- sitemap-index.xml -->
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>https://example.com/sitemap-categories.xml</loc>
<lastmod>2026-05-28</lastmod>
</sitemap>
<sitemap>
<loc>https://example.com/sitemap-products-new.xml</loc>
<lastmod>2026-05-28</lastmod>
</sitemap>
<sitemap>
<loc>https://example.com/sitemap-products-bestsellers.xml</loc>
<lastmod>2026-05-20</lastmod>
</sitemap>
</sitemapindex>
Dans votre sitemap produits, utilisez le champ lastmod réel (date de dernière modification en base) et non une date statique. Google utilise ce signal pour prioriser sa visite.
Commande Symfony pour mettre à jour le sitemap automatiquement
// src/Command/UpdateSitemapCommand.php
#[AsCommand(name: 'seo:sitemap:update')]
class UpdateSitemapCommand extends Command
{
public function __construct(
private readonly ProductRepository $productRepository,
private readonly SitemapGenerator $sitemapGenerator,
) {
parent::__construct();
}
protected function execute(InputInterface $input, OutputInterface $output): int
{
$io = new SymfonyStyle($input, $output);
$recentlyModified = $this->productRepository->findModifiedSince(
new \DateTimeImmutable('-24 hours')
);
$this->sitemapGenerator->regenerate($recentlyModified);
$io->success(sprintf('%d produits mis à jour dans le sitemap', count($recentlyModified)));
return Command::SUCCESS;
}
}
Étape 6 : surveiller le crawl budget avec GSC
Google Search Console fournit deux rapports essentiels pour le suivi :
- Rapport de couverture : "Discovered – currently not indexed" signale que Googlebot a trouvé des URLs mais n'a pas le budget pour les crawler. Si ce nombre augmente, votre crawl budget est saturé.
- Statistiques de crawl (GSC → Paramètres → Statistiques de crawl) : consultez la répartition des codes réponse et le nombre de requêtes/jour. Une chute soudaine des requêtes indique souvent un problème de performance serveur.
Configurez une alerte sur le KPI "Discovered – currently not indexed" : si le ratio dépasse 20% de vos URLs connues, investiguez immédiatement.
Récapitulatif : checklist crawl budget PrestaShop
- Analyser les logs serveur pour identifier la répartition du crawl Googlebot
- Bloquer les paramètres sans valeur SEO dans
robots.txt(?order=,?search_query=...) - Appliquer
noindex, followsur la pagination et les tris produits - Mettre des canonicals sur les facettes qui doivent être crawlées
- Optimiser le TTFB pour maximiser le crawl rate (objectif <200 ms)
- Corriger les chaînes de redirections (pas plus d'un saut)
- Segmenter le sitemap par priorité avec des
lastmodréels - Monitorer "Discovered – currently not indexed" dans GSC
La gestion du crawl budget est un travail continu, pas un one-shot. Sur un catalogue qui évolue quotidiennement, une commande Symfony planifiée pour régénérer le sitemap et auditer les redirections vous économisera des mois d'indexation perdue.
Besoin d'aide pour auditer ou optimiser le crawl budget de votre PrestaShop ? Contactez-moi pour en discuter !